Cambridge Analytica

Political data firm Cambridge Analytica obtained the data of 50 million Facebook users, constructed 30 million personality profiles, and sold the data to US politicians seeking election to influence voters, without the users’ consent. Although this was revealed in 2015, in March 2018 a former employee of the firm came forward with more details, placing Facebook’s practices under intense scrutiny, and raising questions as to the responsibility of the Internet industry. The facts, wide-reaching implications, and open questions are explained below.
How was the data obtained?
In 2014, a researcher from Cambridge University, Alexandr Kogan, developed an app called ‘thisismydigitallife’. The app paid users ($1‒$2) to take a personality quiz, but to take the quiz, users had to consent to give the app access to their Facebook profiles and those of their friends. The paid task was advertised to remote freelance workers on Mechanical Turk, a crowdsourcing online marketplace controlled by Amazon.
Over 270,000 users took the quiz; however, the app was able to access the full profile of over 50 million friends’ accounts – which, at the time, Facebook’s API (application program interface, i.e., the platform for building applications) allowed by default. To harvest such data through Facebook’s API, the researcher obtained a licence from Facebook, ‘for research purposes only’.
How was the data used?
Kogan violated his agreement by giving the data to political data firm Cambridge Analytica, which was co-founded by Republican donor Robert Mercer. The firm reportedly funded $7 million for Kogan’s exercise.
Once in Cambridge Analytica’s hands, the data of 30 million users (out of the original 50 million) was matched with other records to construct personality profiles on millions of American voters. Cambridge Analytica classified voters using five personality traits known as OCEAN – Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism. The aim was to identify the personalities of American voters and influence their behaviour, using psychographic modelling techniques.
In December 2015, The Guardian revealed that Cambridge Analytica was selling psychological data to Ted Cruz’s presidential campaign.
Although the New York Times reported that Facebook did not verify how the information was being used, Facebook said it had removed the app in 2015 after learning of the subsequent violation of platform policies. Kogan, Cambridge Analytica, and another former employee Christopher Wylie certified to Facebook that they had deleted the data.
Once Donald Trump became the presumptive nominee, Cambridge Analytica made contact with, and was later engaged by, his campaign team. The first payment of $100,000 was made in July 2016. The relationship is now under scrutiny by the Special Council investigating the alleged Russian interference in the US election. There may also be ties with the UK’s Leave.EU campaign, the group which campaigned for Brexit in 2016.
In March 2018, the former Cambridge Analytica employee, Christopher Wylie, provided documents and first-person testimony to The Times and the Observer which confirmed the details. He also confirmed that a large amount of the data was still on the company’s servers. How much the data actually contributed to influencing voters is still being debated and is unclear.
Implications for digital policy
The revelations have placed the practices – and responsibilities – of Facebook and other companies under intense scrutiny.

Once considered as separate industries, the media and the Internet industry have now converged around the data model.
In this model, users provide their own data in exchange for using the service. Data in large quantities is then used for advertising and marketing purposes. For example, in 2017, Facebook’s advertising revenues were close to $40 billion; that same year Google’s revenues from advertising reached over $27 billion.
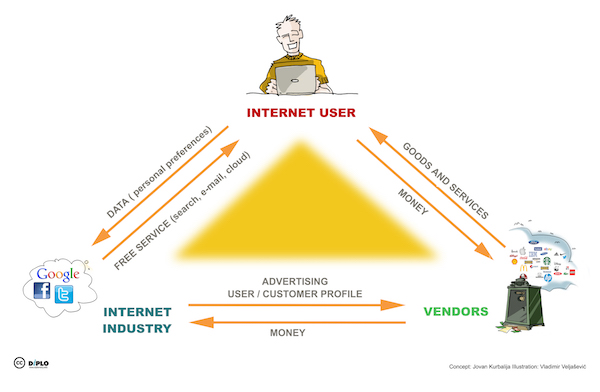
Harvested data has many more uses. Amazon is using customer data to target deals. Uber is using customer data to develop autonomous vehicles. Hardware companies are also collecting data: Recent Wikileaks revelations show that a smart TV manufacturer was allegedly collecting data on users’ viewing habits.
This ‘gold rush’ for data means that any issues, challenges, or risks associated with the industry’s data model are increasing exponentially.

One of the main questions relates to the liability of intermediaries regarding the data they collect, and the users’ rights over their personal data.
The data trail in the Cambridge Analytica case shows that two main actors were involved: the network (Facebook), and third parties (the researcher, Cambridge Analytica, and the political campaigns). It also raises several questions:
Why did Facebook’s API allow the automatic gathering of friends’ data, and how will potential breaches of data (which was collected back then) be dealt with? If the terms between Facebook and third parties were breached, who is responsible?
Data breaches, misuse of data, and breaches of users’ rights are inherently connected.

Facebook and other companies collect a large amount of data. The company not only records the ‘likes’ but also geographical information based on GPS or Wifi signal, information from websites and apps which the user logs onto via their Facebook login credentials, and any contact information the user allows Facebook to access. Facebook even creates ‘shadow profiles’ of nonusers, inferred from other data.
One of the main criticisms levelled against both Internet companies and authorities relates to the large amounts of data points the companies are allowed to harvest.
Once harvested, legal and ethical questions also arise, related to how the data and data analyses will be used.

Although much of the criticism is about the industry’s practices, most of the data is collected from the users themselves, who agree to give away the data in exchange for a good or service. It is therefore legitimate to ask whether users actually understand the terms of this ‘deal’.
Studies show that users either do not understand the data trade-off, or they are unaware of the implications related to their data when they accept the companies’ terms and conditions. There is also a significant number of users who may be aware, but see the exchange of information as an inevitable trade-off. Only a small group of users indicate they see the exchange of data for personalised content as a fair deal. Terms of service written in complicated legal jargon are still commonplace; so are blanket provisions relating to the user and sharing of users’ data.
The main questions are: Who should safeguard the users’ position vis-à-vis the bargaining power of the Internet industry? Who should ensure that users are well-informed about the implications of their consent, and any potential alternatives?

While users did consent to giving Facebook their data, the network did not specifically inform them that their data had been passed on to the Cambridge Analytica researcher.
Although the transfer of data may be legal due to blanket provisions in the company’s data policy, the lack of disclosure in this case could violate laws in Britain and in many American states. Cambridge Analytica’s connection to the US elections may also be illegal. Regulators in the USA and the UK are investigating.
Tougher rules in Europe will come into effect on 25 May 2018. The EU’s General Data Protection Regulation (GDPR) obliges companies handling the personal data of EU citizens, regardless of where the company is located, to obtain clear and unequivocal consent for the processing of data. It also includes hefty fines for non-observance.

The practice of collecting data from users in exchange for services or content has also raised questions related to compensating users for their data.
Users give away significant amounts of data without financial compensation. The data has contributed significantly to the revenues of the Internet industry.
Two trends have emerged with the aim of compensating users, or giving some of the value back to society.
The first relates to governments’ push for taxing the industry. Several countries in the EU have proposed new concepts for taxing Internet companies’ revenue, in lieu of the standards provided in the traditional tax system which are not proving adequate enough. In March 2018, the European Commission proposed short-term and long-term plans that better reflect the online nature of digital businesses. In parallel, the Organisation for Economic Co-operation and Development (OECD) has issued its interim report which highlights the main challenges of taxing the digital economy, and the need for a global approach to tax rules.
The second relates to calls for users to be compensated more directly. One emerging idea is that of a data fund: Just like Alaskan citizens receive annual dividends from the Alaska Permanent Fund, a constitutionally established fund funded by oil revenues, digital companies would be required to pay a percentage of their data revenue into a sovereign wealth fund, and pay out an annual dividend to users.

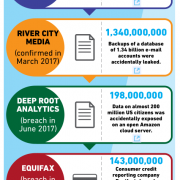
Data breaches are on the rise, and typically, users learn about a data breach only after it has been revealed by the companies. In some cases, notifications of a breach come long after it happens:
In 2016, news of a breach that affected the data of 57 million Uber drivers was disclosed by the company a year after the breach took place. At this time, it also emerged that after the company’s servers had been breached in 2016, Uber paid $100,000 to the intruders to delete the data and keep silent.
In the Cambridge Analytica case, a Facebook executive said: ‘This was unequivocally not a data breach… No systems were infiltrated, no passwords or information were stolen or hacked.’ The executive said that the violation had been committed only by Cambridge Analytica, whose app ‘did not follow the data agreements’.
At the time, however, the researcher was able to exploit a loophole in Facebook’s API which allowed the developer to gather information not only on the users of the app, but all the users’ Facebook friends.
This highlights a larger debate as to what extent Facebook is able to remove potentially dangerous loopholes, and secure its systems and the users’ data as it changes hands.

The original source of data used by Cambridge Analytica was collected from remote freelance workers who were paid small amounts of money is exchange for their data.
Although the case did not directly raise any issues with regard to the remote workers, it does bring to the fore the social dimension related to workers in the gig economy.